2018年中國互聯網保險行業發展趨勢分析 新型技術助力產品創新發展與技術咨詢
2018年,中國互聯網保險行業在政策支持、市場需求和技術創新的多重驅動下,展現出蓬勃的發展態勢。隨著大數據、人工智能、區塊鏈和物聯網等前沿技術的深度融合,行業正經歷一場深刻的變革,推動產品創新和服務升級。本文將從行業趨勢、技術創新應用以及技術咨詢的作用三個方面進行分析。
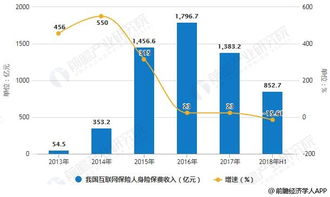
從行業整體趨勢來看,2018年中國互聯網保險市場保持高速增長。消費者對便捷、個性化保險產品的需求日益增長,互聯網平臺成為保險銷售的重要渠道。政策層面,監管機構加強了對互聯網保險的規范,強調風險防控和消費者權益保護,這為行業的健康發展奠定了基礎。同時,市場競爭加劇,傳統保險公司與科技公司合作,加速數字化轉型,推動產品多樣化和服務智能化。
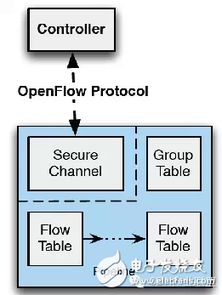
新型技術在互聯網保險產品創新中發揮了核心作用。大數據技術的應用,使保險公司能夠更精準地分析用戶行為和風險數據,從而設計出個性化、動態定價的保險產品,例如基于駕駛行為的車險或健康監測的醫療保險。人工智能在客服、核保和理賠環節實現自動化,提升了效率和用戶體驗,如智能客服機器人和AI驅動的欺詐檢測系統。區塊鏈技術則增強了數據安全性和透明度,用于構建去中心化的保險合約和智能合約,減少糾紛。物聯網設備,如可穿戴設備,實時收集健康數據,支持預防性保險產品的開發。這些技術不僅優化了現有產品,還催生了新型險種,如共享經濟保險和網絡安全保險,滿足了新興市場的需求。
技術咨詢在互聯網保險發展中扮演了關鍵角色。隨著技術應用的復雜性增加,保險公司面臨系統集成、數據安全和合規性等挑戰。專業的技術咨詢服務幫助這些企業評估技術風險、制定數字化戰略,并實施定制化解決方案。咨詢機構提供市場洞察、技術選型和實施指導,助力企業快速適應變化,降低成本并提升競爭力。例如,在2018年,許多保險公司通過與咨詢公司合作,成功部署了云平臺和AI工具,實現了業務的規模化拓展。
2018年中國互聯網保險行業在技術創新驅動下,呈現出產品多元化、服務智能化的特點。未來,隨著5G、量子計算等技術的興起,行業將進一步深化變革。企業應積極擁抱技術,并借助專業咨詢,以抓住發展機遇,應對潛在挑戰,實現可持續發展。
如若轉載,請注明出處:http://m.iido.org.cn/product/31.html
更新時間:2026-06-19 17:41:55